
The following code looks to compare two approaches to scraping football schedule data from ESPN: a direct web-scraping technique using bs4 against Pandas built-in read_html method.
The first method involves using requests and bs4 (Beautiful Soup) to grab and parse the data before formatting into a pandas DataFrame.
The second method involves using pandas read_html to accomplish similar results.
Both are implemented with the concurrent.futures Python package to capture multiple seasons using a ProcessPool.
Data only encompasses 2003 - Present seasons.
These are the hot, single packages in your area that we'll be using:
import time
import concurrent.futures
import requests
from bs4 import BeautifulSoup
import pandas as pd
USER_AGENT = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
In order to run the read_html method you will need to install the 'lxml' package using pip3:
pip3 install lxml
Let's understand what data we're looking for. It exists on ESPN here: Bengals 2021 Schedule (If this is some point in the future where this URL is deprecated, the code will have to be adjusted. I am sorry I could not help you during this time. I understand how frustrating the 697th link you've clicked on can be and I wish you luck in your journey).
Here is a picture of the schedule:
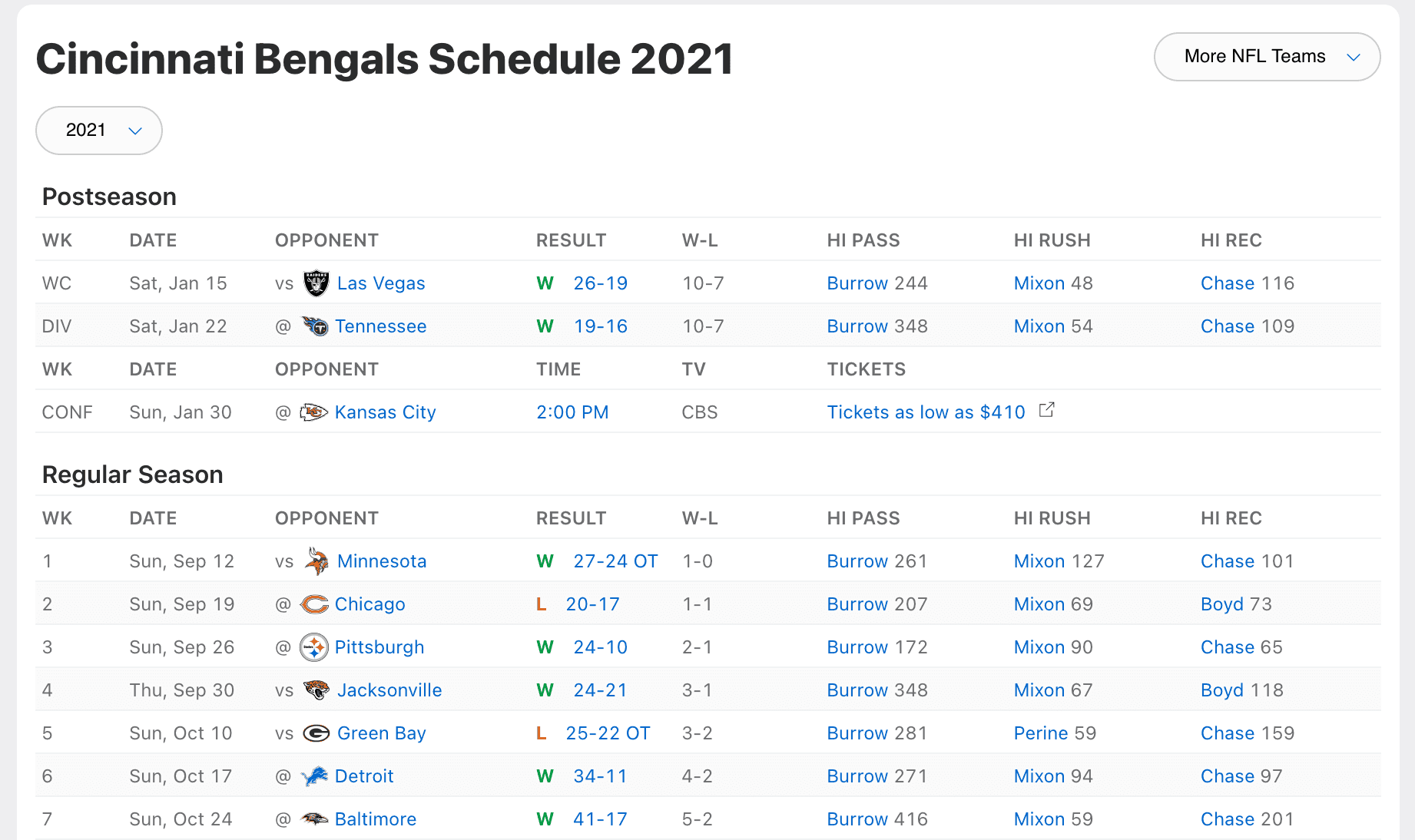
...and here is the main designation for our script:
MAX_PROCESS = 10
if __name__ == '__main__':
base_url = 'https://www.espn.com/nfl/team/schedule/_/name/cin/season/'
sample_url = 'https://www.espn.com/nfl/team/schedule/_/name/cin/season/2021'
seasons = [base_url + str(i) for i in range(2003, 2022)] * 20
start_time_bs4 = time.time()
try:
with concurrent.futures.ProcessPoolExecutor(max_workers=MAX_PROCESS) as executor:
executor.map(scrape_espn, seasons)
except Exception as e:
print(e)
print("Time to complete is: {}".format(time.time() - start_time_bs4))
print(scrape_espn(sample_url))
start_time_pandas = time.time()
try:
with concurrent.futures.ProcessPoolExecutor(max_workers=MAX_PROCESS) as executor:
executor.map(read_html_espn_pandas, seasons)
except Exception as e:
print(e)
print("Time to complete is Process: {}".format(time.time() - start_time_pandas))
print(read_html_espn_pandas(sample_url))
The base_url helps construct a list of available seasons from 2003 to the current year. Time is time man, and it continues forward, but had to start somewhere so start_time_bs4 is going to be our beginning to the first method: Beautiful Soup dm'ing your NFL team.
Both methods will use concurrent.futures.ProcessPoolExecutor to speed the process up because we're focusing on CPU bound operations for parsing/searching the HTML response. ThreadPoolExecutor can also be used; however, during performance testing the increase wasn't as significant. If more season data was available, or if we wanted to expand this script to capture every team's NFL schedule performance, it would be interesting to retest ProcessPoolExecutor versus ThreadPoolExecutor. The increase in request volume may lend greater performance enhancements to ThreadPoolExecutor by reducing in-between downtime.
Either way, this allows us to request multiple seasons concurrently because I want my data and I want it NOW! MAX_PROCESS sets the maximum number of workers we want going as we map scraping functions over our seasons list.
def scrape_espn(map_url):
map_url, html = fetch_espn_results(map_url)
results = parse_espn_results(html)
return results
def fetch_espn_results(map_url):
assert isinstance(map_url, str)
response = requests.get(map_url, headers=USER_AGENT)
response.raise_for_status()
return map_url, response.text
def parse_espn_results(html):
soup = BeautifulSoup(html, 'html.parser')
espn_table_name = soup.find('h1', class_='headline').text
espn_table_columns = soup.find('colgroup').contents
espn_table_body = soup.find('tbody')
espn_table_rows = espn_table_body.find_all('tr')
data_set = [[espn_table_name]]
for row in espn_table_rows:
espn_data_values = row.find_all('td')
data_row = [data.get_text(separator=' ') for data in espn_data_values]
data_set.append(data_row)
pandas_column_names = [ 'Col_' + str(i) for i in range(1, len(espn_table_columns)+ 1)]
df = pd.DataFrame(data_set, columns=pandas_column_names)
df.fillna('', inplace=True)
return df.head()
The first function is scrape_espn, which will call another function fetch_espn_results with the input URLs from our seasons list.
We will assert the URL is a string to properly pass it to requests for the response text. That result is passed into parse_espn_results function, which parses the HTML from our earlier table. We get the 'h1' tag for the table's headline so the current season year is included.
Next, because ESPN decides to change headlines based on season scheduling and upcoming game information, we don't have direct header naming conventions we can pass into the final DataFrame. Instead, we need to count the contents of the <colgroup> tag.
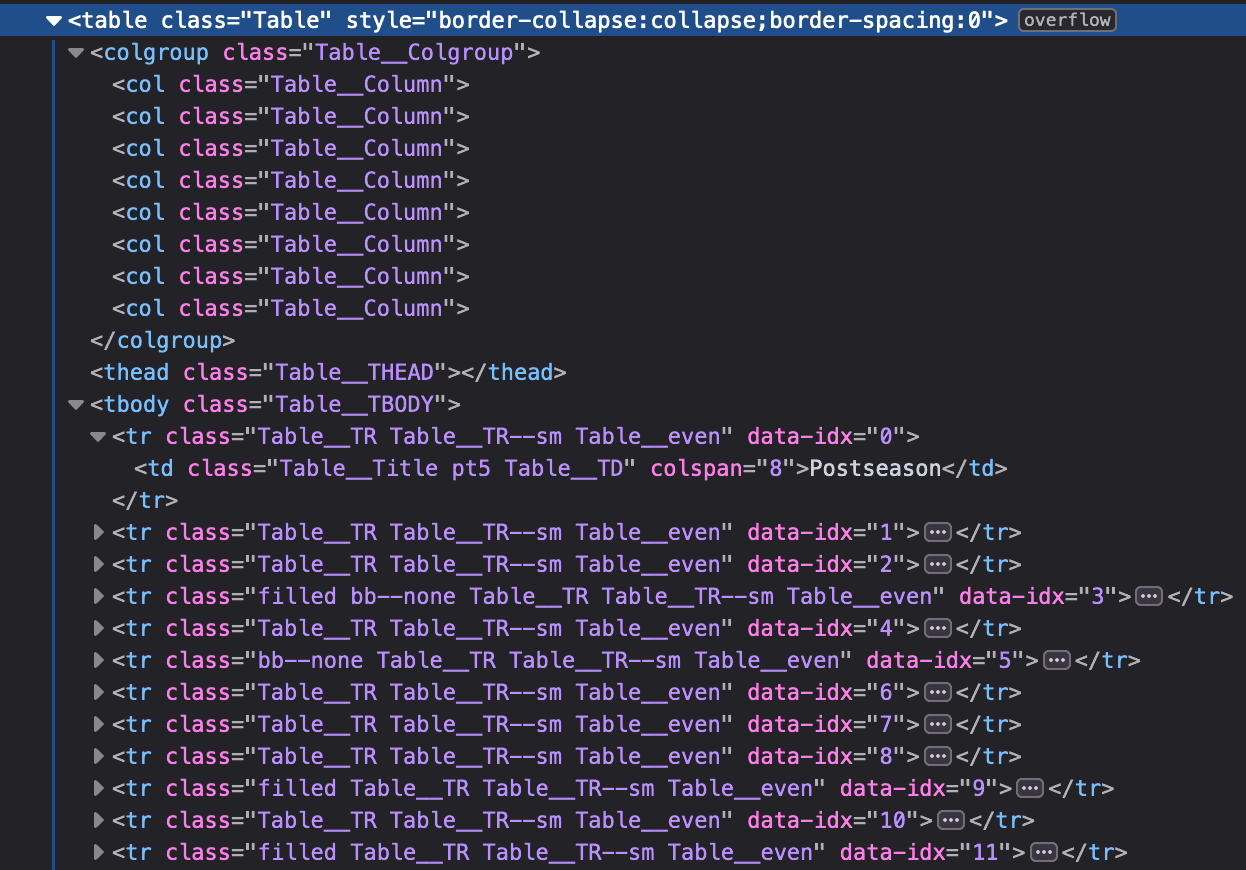
This isn't required based on the current webpage conditions; however, statically implementing the current number of columns is pointless if they start changing things.
Now, we get the Table body with the <tbody> tag in order to locate each Table row with tag <tr>
Our data_set will begin with the season Table header so that our final DataFrame is distinguishable upon visualization.
data_set = [[espn_table_name]]
Iterating through each row we've gathered, we will grab the data values located across them. Initially, all the data values are stored in the <td> tags:
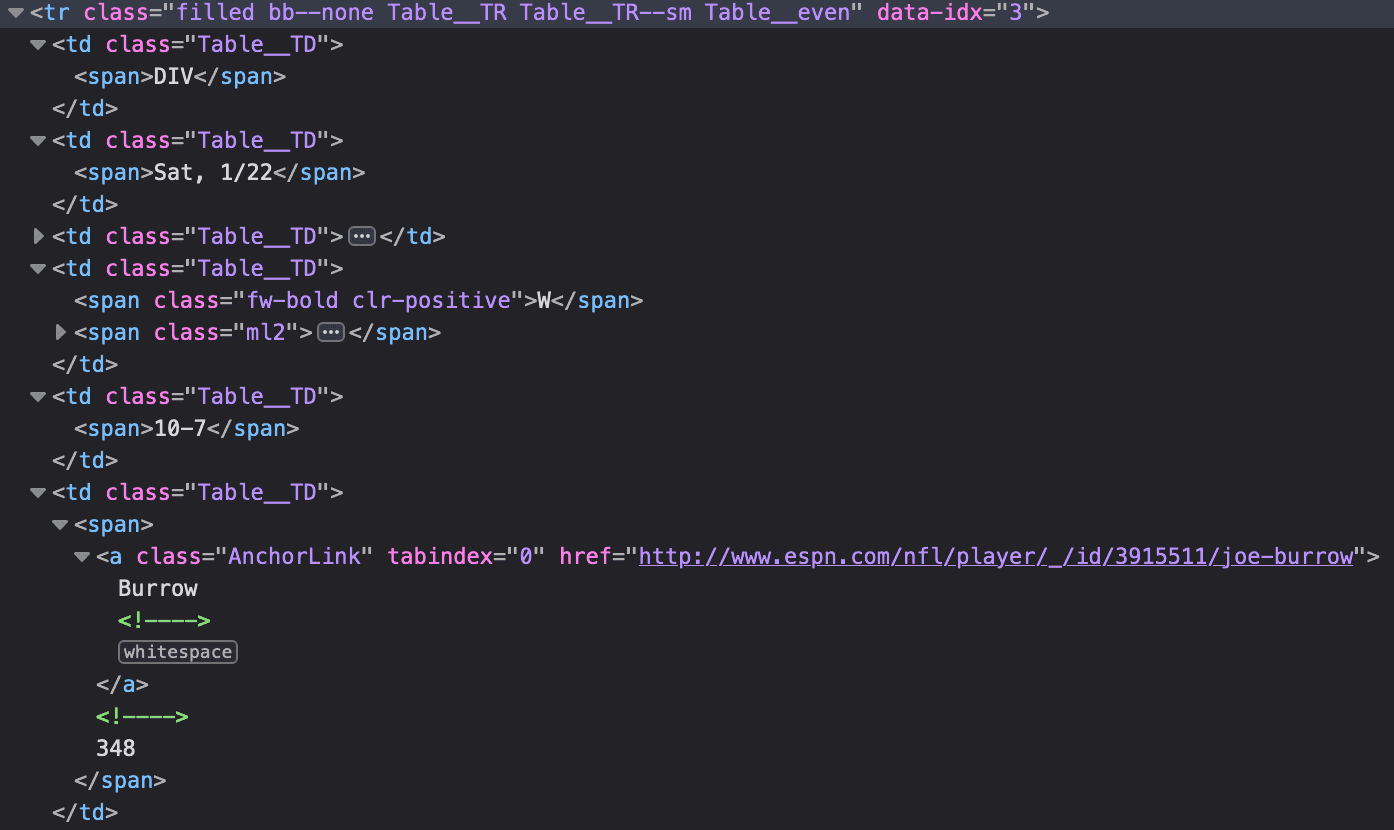
Using list comprehension, we can capture the text portion of that tag (i.e. the actual data value) and format it as a list representing a data row to be appended to our data set
for row in espn_table_rows:
espn_data_values = row.find_all('td')
data_row = [data.get_text(separator=' ') for data in espn_data_values]
data_set.append(data_row)
The final bits of code are to create the pandas DataFrame we want to output to visualize the football schedule on ESPN in our console or wherever local data representation is sold. We make the columns, we make the DataFrame based on our data_set/column names, we replace all those disgusting NaN values with a blank string so that it looks pretty, and we print the head() of each DataFrame.
pandas_column_names = [ 'Col_' + str(i) for i in range(1, len(espn_table_columns)+ 1)]
df = pd.DataFrame(data_set, columns=pandas_column_names)
df.fillna('', inplace=True)
return df.head()
Okay, now that that is out of the way here is the code for the second method: Using pandas read_html method:
def read_html_espn_pandas(map_url):
df2 = pd.read_html(map_url).pop()
df2.fillna('', inplace=True)
return df2.head()
The season URLs are passed into the function, in which pandas returns the table in a list. The reason it returns a list is because read_html is a greedy little piggie. It will grab any Table listed on the page, so pop() is necessary to pop that DataFrame just like you do. It's removed from the list and stored as a DataFrame object. Then we hit it with the fillna() before returning the DataFrame's head.
Alright my guy, but why did you write so many lines when one simple function based in pandas might do it in a few?
A few considerations.
- I enjoy torturing myself with an increasingly questioning behavior towards my baseline.
- The
read_htmlversion looks icky, which means while the upfront time savings may be sweet, producing a readable format for visualization will take additional time. - If ESPN decided to add another table to the page the first page popped may not be correct for the year. The bs4 version could take the
class_keyword argument infind()to identify the approapriate table if they made that design change.
Here's an example output from each method along with Time Comparisons based on 20 repeated simulations for both Process and Thread Pool Executors:
bs4 method:
Process: 16.67 sec
Thread: 28.83 sec
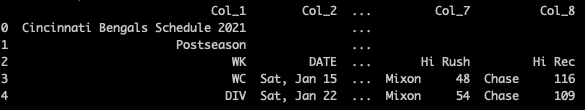
pandas read_html method:
Process: 9.17 sec
Thread: 14.48 sec

The code can be updated to any other NFL team besides my Bengal cuties, with the code base located on GIT here: Repository
To end this, here are additional considerations if you run into an issue.
Considerations:
The bs4 method will naturally take longer since it has to parse through the response, and the on page table is a slightly jumbled. Games yet to be played for the current season have ticket and TV time information, causing those headers to be different.
When running pd.read_html on MacOS, SSL certification can throw an error.
Navigate to the respective application folder for Python3 and run
Install Certifications.command to resolve. 'lxml' also has to be installed.
If you see nothing appearing on the print line it's probably a lack of 'lxml'
The pandas method will not return the respecitve season's year. The data tables only contain the day/month for date. Since the ProcessPool will return results in random order as they finish, a designation for the year will need to be added in the tables to give proper context.
FULL CODE:
import time
import concurrent.futures
import requests
from bs4 import BeautifulSoup
import pandas as pd
USER_AGENT = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
def scrape_espn(map_url):
map_url, html = fetch_espn_results(map_url)
results = parse_espn_results(html)
return results
def fetch_espn_results(map_url):
assert isinstance(map_url, str)
response = requests.get(map_url, headers=USER_AGENT)
response.raise_for_status()
return map_url, response.text
def parse_espn_results(html):
soup = BeautifulSoup(html, 'html.parser')
espn_table_name = soup.find('h1', class_='headline').text
espn_table_columns = soup.find('colgroup').contents
espn_table_body = soup.find('tbody')
espn_table_rows = espn_table_body.find_all('tr')
data_set = [[espn_table_name]]
for row in espn_table_rows:
espn_data_values = row.find_all('td')
data_row = [data.get_text(separator=' ') for data in espn_data_values]
data_set.append(data_row)
pandas_column_names = [ 'Col_' + str(i) for i in range(1, len(espn_table_columns)+ 1)]
df = pd.DataFrame(data_set, columns=pandas_column_names)
df.fillna('', inplace=True)
return df.head()
def read_html_espn_pandas(map_url):
df2 = pd.read_html(map_url).pop()
df2.fillna('', inplace=True)
return df2.head()
MAX_PROCESS = 10
if __name__ == '__main__':
base_url = 'https://www.espn.com/nfl/team/schedule/_/name/cin/season/'
sample_url = 'https://www.espn.com/nfl/team/schedule/_/name/cin/season/2021'
seasons = [base_url + str(i) for i in range(2003, 2022)] * 20
start_time_bs4 = time.time()
try:
with concurrent.futures.ProcessPoolExecutor(max_workers=MAX_PROCESS) as executor:
executor.map(scrape_espn, seasons)
except Exception as e:
print(e)
print("Time to complete is: {}".format(time.time() - start_time_bs4))
print(scrape_espn(sample_url))
start_time_pandas = time.time()
try:
with concurrent.futures.ProcessPoolExecutor(max_workers=MAX_PROCESS) as executor:
executor.map(read_html_espn_pandas, seasons)
except Exception as e:
print(e)
print("Time to complete is Process: {}".format(time.time() - start_time_pandas))
print(read_html_espn_pandas(sample_url))